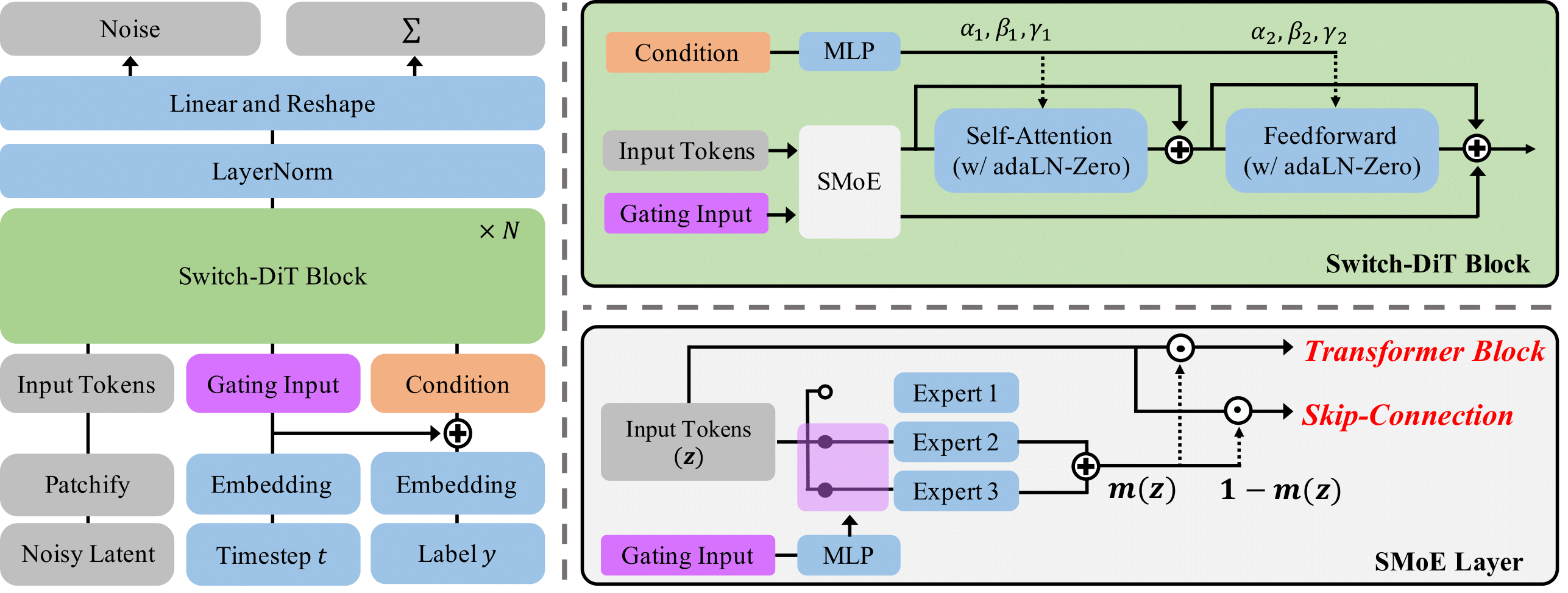
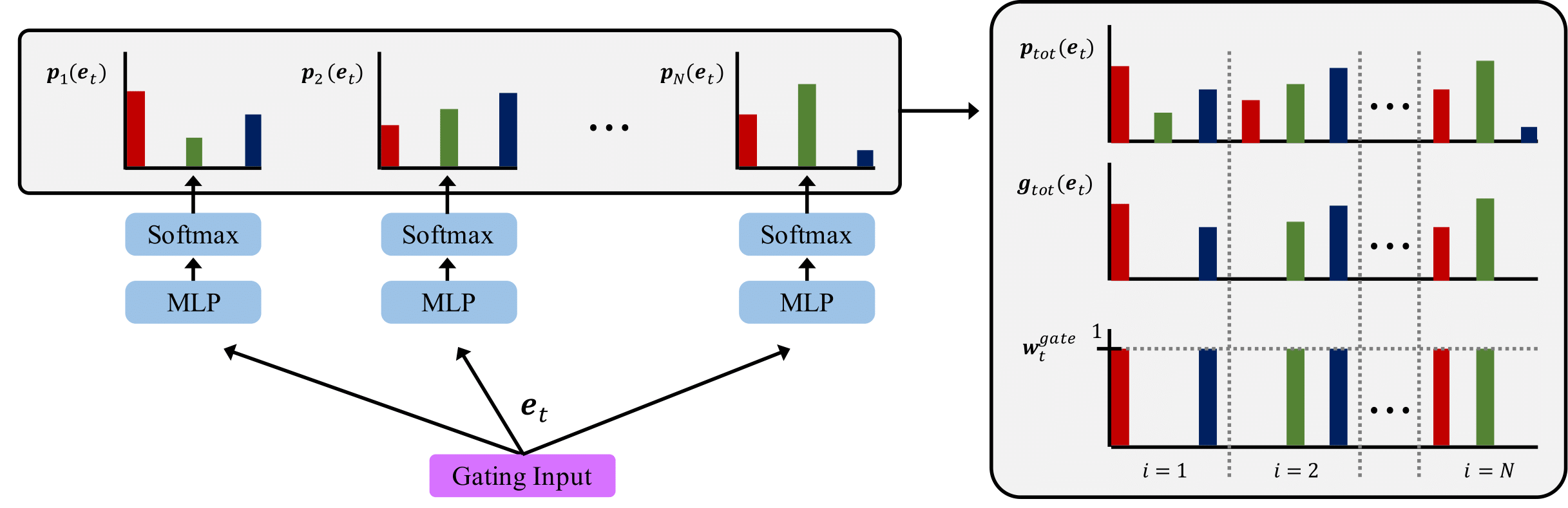
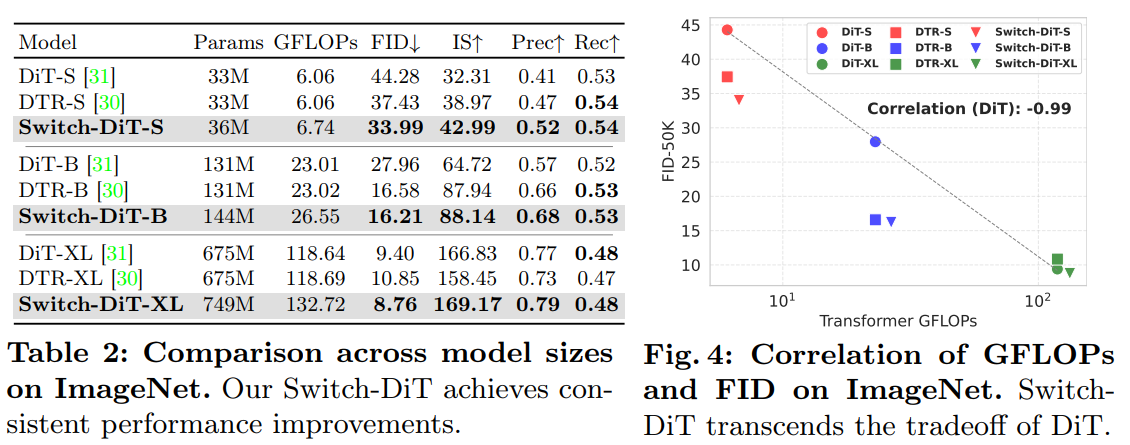
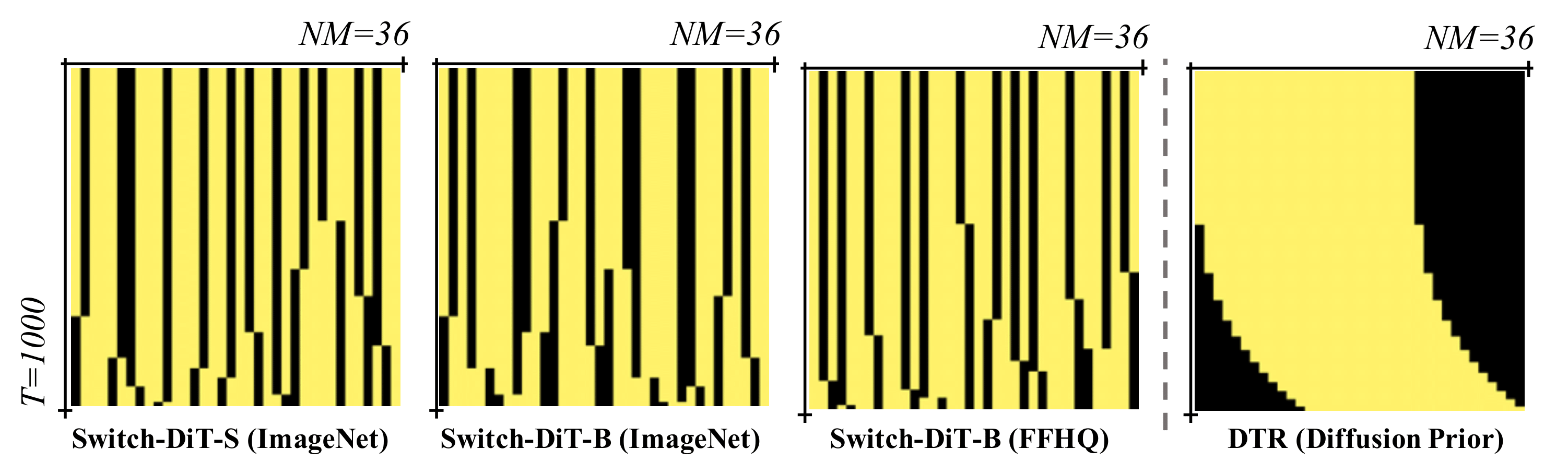
1. Conceptualizing diffusion models as a form of multi-task learning.
Diffusion models are conceptualized as a multi-task learning, where they address a set of denoising tasks at each timestep \(t\). These tasks focus on reducing noise, which is trained to minimize the noise prediction loss \(L_{noise, t} = ||\epsilon - \epsilon_\theta(x_t, t)||_2^2\).